·专家警示,ChatGPT等人工智能推动的机器人可能很快就“耗光宇宙中的文字”。同时,用AI产生的数据“反哺”AI或造成模型奔溃。
将来模型训练应用的高品质数据可能越来越昂贵,网络迈向碎片化和封闭化。·“当大模型发展迈向更深层,例如行业大模型,所需的数据就不是互联网免费公开的信息了,要训练出精度极高的模型,需要的是领域专业技能,乃至商业机密类别的知识。想让大家奉献这种词库,肯定需要有一种利益分配原则。”做为人工智能基础设施的“三驾马车”之一,数据的重要性一直显而易见。随着大语言模型风潮进到高峰期,业内对数据的认知度史无前例。
7月初,加州大学伯克利分校计算机科学教授、《人工智能——现代方法》作者斯图尔特·罗素(Stuart Russell)发出警告称,ChatGPT等人工智能推动的机器人可能很快就“耗光宇宙中的文字”,通过收集大量文原本练习机器人技术“逐渐碰到困难”。科研机构Epoch可能,机器学习数据有可能在2026年前耗光全部“高品质语言数据”。“数据质量和信息量将是下一阶段大模型水平涌现重要中的重要。
”中信智库专家委员会主任、中信建投证券研究所优点武超在2023世界人工智能大会(WAIC)上分享了一个计算,“将来一个模型的好坏,20%由算法确定,80%由数据质量确定。下面高质量数据将是提高模型特性的重要。”但是,高品质数据从哪里来?
目前,数据行业仍然面临多种亟待解决的问题,例如数据质量的标准是什么,如何促进数据分享和流通,怎样设计定价和分派盈利体系。高品质数据吃紧上海数据交易所副总韦志林7月8日在接受媒体采访时表示,在数据、算率、算法“三驾马车”里,信息是最核心、最长久、最基础性的因素。
大型语言模型(LLM)有如今令人惊艳的表现,背后的体制被归纳为“智能涌现”,简单理解得话,就是以前没教过AI的技能它现在也会了。而大量的数据集是“智能涌现”的重要基础。大型语言模型是有着数十亿到数万亿参数深度神经网络,被“预训练”于数TB(Terabytes,1TB=1024MB)极大的自然语言词库上,包含结构化数据、在线图书和其它内容。
中电金信研究院副院长单海军在2023世界人工智能大会期间对磅礴科技表示,大模型实质上是几率生成模型,其主要亮点在于能理解(前后文提醒学习)、能推理(思维链)与有价值观(人们反馈增强学习)。ChatGPT较为大的突破要在GPT-3出现时,大约1750亿参数量,信息量为45个TB。2018年到2022年初从GPT-1到Gopher的精选语言模型的所有数据集的综合视图。未加权尺寸,以GB为基准。
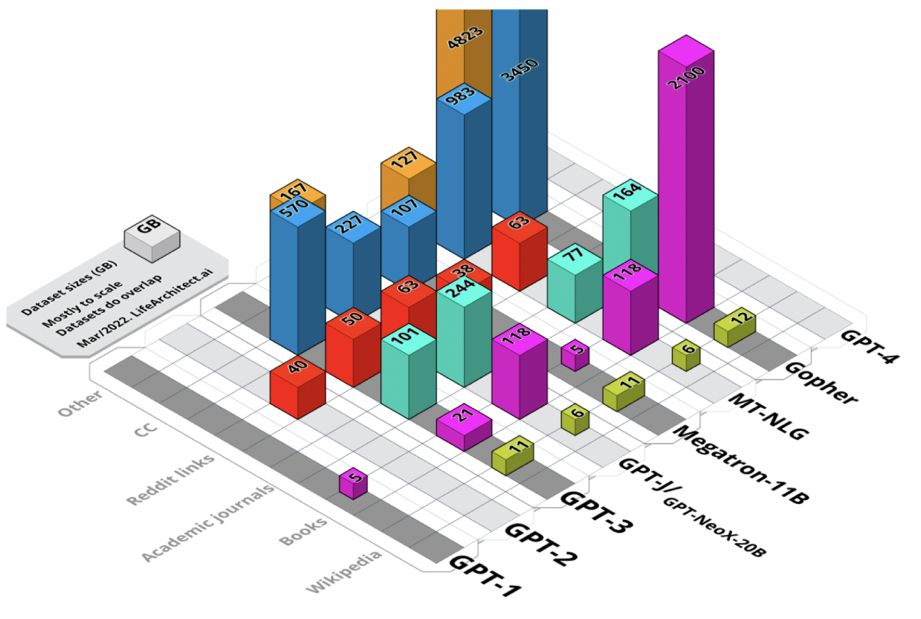
“OpenAI一直以来努力的方向全是寻求更多的优质数据,深度解读现有的数据,从而使自己能力越来越强。
”7月12日,复旦大学教授、上海市数据科学重点实验室主任肖仰华对磅礴科技表示,“获得规模性、高品质、多元化的数据,并分析这些信息,可能是促进大模型发展的重要构思之一。
”但是,高品质数据已经吃紧。人工智能研究人员小组Epoch上年11月开展的一项研究可能,机器学习数据有可能在2026年前耗光全部“高品质语言数据”。而这项研究发布时全球范围内的大模型潮还没有出现。根据该研究,“高品质”集中的表达数据来自“书本、新闻文章、科学论文、维基百科和过滤的网络内容”。此外,OpenAI等生成式AI开发机构为练习大型语言模型所进行的数据采集行为也越来越受异议。
6月底,OpenAI遭集体诉讼,被指盗取“很多个人数据”来训练ChatGPT。包含Reddit和推文在内的社交网络并对平台数据被随意使用表示不满,马斯克7月1日为此原因对推文阅读数量实施了临时限定。
7月12日,罗素接受科技财经媒体Insider的采访时表示,很多报导尽管未经证实,但都详细说明了OpenAI从个人由来买了文本数据集。虽然这种选购有各种可能的描述,但“自然推理是没有一定的高品质公共数据。”有专家提出,也许在数据耗光时会出现新的解决方案。例如,能让大模型自身不断形成新数据,然后经过某类品质过虑,相反再用以训练模型,这被称为自我学习或“反哺”。
可是,依据牛津大学、剑桥大学、伦敦帝国学院等组织的研究人员今年5月在预印本平台arXiv上发表的论文,AI用AI形成的数据进行练习,会导致AI模型存有不可逆转的缺点,她们将其称之为模型奔溃(Model Collapse)。这意味着将来模型训练应用的高品质数据可能越来越昂贵,网络迈向碎片化和封闭化,内容创作者可能竭尽所能防止其内容被免费爬取。可以看出,高品质数据的获取会越来越难。“大家现在大多数的信息来源或是互联网,后半年数据从哪来?我觉得这个很重要,最后大家会拼私数据,或者你有我没有的信息。
”上海人工智能实验室青年科学家、OpenDataLab责任人何聪辉在2023世界人工智能大会上提到。武超还对磅礴科技表示,下面谁拥有更高质量的数据,或者能产生源源不绝的高品质数据,将成为效能提升的关键。“以数据为核心”的烦恼何聪辉觉得,下面全部模型研制的方式会逐渐从“以模型为核心”变为“以数据为核心”。但以数据为核心有一个困惑——欠缺规范,数据