mysql视频教程栏目介绍利用分片解决百亿数据的存储

推荐(免费):mysql视频教程
这是一个关于我们在多个 MySQL服务器上分割数据的技术研究。我们在2012年年初完成了这个分片方法,它仍是我们今天用来存储核心数据的系统。
在我们讨论如何分割数据之前,让我们先了解一下我们的数据。心情照明,巧克力草莓,星际迷航语录……
Pinteres 是你感兴趣的所有东西的发现引擎。从数据的角度来说,Pinterest 是世界上最大的人类兴趣图集。有超过500亿的 Pin 被 Pin 友们保存在10亿块图板上。 用户再次 Pin,喜欢其他人的 Pin(粗略地说是一个浅显的复制品),关注其他 Pin 友,画板和兴趣,然后查看主页上所订阅Pin友的所有资讯。 太好了! 现在让它扩大规模!
成长的痛
在2011年我们取得了成功。 在 一些 评估报告里,我们的发展比其他的初创公司要快得多。在2011年9月,我们每一项基础设备都超出了负载。我们应用了一些 NoSQL 技术,所有这些技术都导致了灾难性的后果。 同时,大量用于读的 MySQL 从服务器产生了大量令人恼火的 bugs,特别是缓存。我们重构了整个数据存储模式。为了使之有效,我们仔细制定了我们的要求。
业务要求
我们的全部系统需要非常稳定,易于操作和易于扩展。 我们希望支持数据库能从开始的小存储量,能随着业务发展而扩展。 所有 Pin友 生成的内容在网站上必须随时可以访问。 支持以确定的顺序请求访问 N 个 Pin在画板中展示(像按照创建的时间,或者按照用户特定的顺序)。对于喜欢的 Pin 友和 Pin友的 Pin 列表等也能按照特定的顺序展示。 为了简单起见,更新一般要保证最好的效果。为了获取最终一致性,你需要一些额外的东西,如分布式 事务日志。这是一件有趣并(不)简单的事情。解决思路及要点备注
解决方案由于需要将海量的数据切片分布到多个数据库实例上,不能使用关系数据库的连接、外键或索引等方法整合整个数据。想想就知道,关联的子查询不能跨越不同的数据库实例。
我们的方案需要负载平衡数据访问。我们憎恨数据迁移,尤其是逐个记录进行迁移,因关系的复杂性,这样非常容易发生错误且加重系统不必要的复杂性。如果必须要迁移数据,最好是逻辑节点集的整体迁移。
为了达到方案实施的可靠迅速,我们需要在我们的分布式数据平台上使用最易于实现、最健壮的技术方案。
每个实例上的所有的数据将被完全复制到一个从实例上,作为数据备份。我们使用的是高可用性的 MapReduce (分布式计算环境) 的 S3 。我们前端的业务逻辑访问后台数据,只访问数据库的 主实例。永远不要让您的前端业务去读写访问从实例 。因为它与 主实例 数据同步存在延迟,会造成莫名其妙的错误,一旦将数据切片并分布,没有一丝理由让你前端业务从 从实例 上读写数据。
最后,我们需要精心设计一个优秀的方案生成和解析我们所有数据对象的 全局唯一标识( UUID ) 。
我们的切片方案
不管怎样,我们需要设计符合我们需求的,健壮的,性能优良和可维护的数据分布解决方案。换句话说,它不能稚嫩(未经广泛验证)。因此,我们的基础设计建立在 MySQL 之上,参见 we chose a mature technology(选择成熟技术) 。设计之初,我们自然会跳开不用那些号称具有自动分布(auto-scaling)新技术能力的数据库产品,诸如 MongoDB,Cassandra 和 Membase 之类的产品,因为它们似乎实施简单却适用性太差(常常发生莫名其妙的错误导致崩溃)。
旁白:强烈建议从底层基础入手,避免时髦新鲜的东东 — 扎扎实实把 MySQL 学好用好。相信我,字字都是泪。
MySQL 是成熟、稳定并且就是好使的关系型数据库产品。不仅我们用它,包括许多知名大公司也使用它作为后台数据支撑,存储着海量的数据。(译注:大概几年前,由于MySQL随着 SUN 被 Oracle 的收购,归到 Oracle 名下。许多公司,如 google,facebook 等由于担心 MySQL 的开源问题,纷纷转到由 MySQL 原作者开发的另一个开源数据库 MariaDB 下)MySQL 支持我们对数据库要求按序数据请求,查询指定范围数据及行(记录)级上的事务处理的技术要求。MySQL有一堆功能特性,但我们不需要那些。由于 MySQL 本身是个单体解决方案,可我们却要把我们的数据切片。(译注:此处的意思是,一个单实例管理海量的数据,势必造成性能问题。现在把一个海量整体数据切片成一个个单体数据集,需要一个强有力的技术解决方案,把一个个的单体整合成一个整体,提高性能还不出错)下面是我们的设计方案:
我们起始使用8台 EC2 服务器,每台服务器都运行一个 MySQL 实例:


每个 MySQL 服务器各自以 主-主备份( master-master replicated )到1台冗余主机作为灾难恢复。我们前台业务只从主服务实例读/写数据 。我建议你也这么做,它简化许多事情,避免延迟故障。(译注:主-主备份( master-master replicated ) 是MySQL数据库本身提供的功能,指两台机器互做备份的一种模式,相对其它模式,如 主-从备份,两台机器数据完全一致,后台同步,每台机器有自己单独 IP 都可访问,可并发读/写访问。但原文作者一再强调的是虽然这两台互为冗余使用 主-主备份,都可访问。但你逻辑上区分 主-从,永远只从其中一个进行读/写。例如,图中所示, MySQL001A 和 MySQL001B 间 主-主备份,但你只从 MySQL001A 进行读/写访问。另:他们使用了16台机器,另8台做从机的可能不是 EC2 也未必)
每个 MySQL 实例可以有多个数据库:

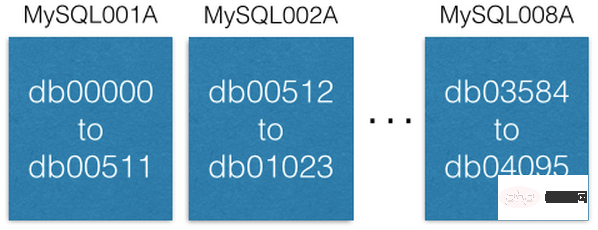
注意每个数据库是如何唯一地命名为 db00000,db00001,直到 dbNNNN。每个数据库都是我们数据库的分片。我们做了一个设计,一旦一块数据被分配到一个分片中,它就不会移出那个分片。但是,你可以通过将分片移动到其他机器来获得更大的容量(我们将在后面讨论这一点)。
我们维护着一个配置数据库表,此表中记录这切片数据库在哪台机器上:
1
2
3
4
5
6
[
{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”},
{“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”},
...
{“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}
]
这个配置表仅当迁移切片数据库或替换主机时修改。例如,一个主实例主机宕掉了,我们会提升它的从实例主机为主实例,然后尽快顶替一个新机器当从实例主机。配置脚本保留在 ZooKeeper 上,当出现上述修改时,通过脚本发送到维护切片服务的机器上进行配置改变。(译注:可发现原作者一直强调的,前端业务仅从逻辑主实例读写数据的好处)。
每个切片数据库保持相同的数据库表及表结构,诸如,有 pins ,boards ,users_has_pins ,users_likes_pins ,pin_liked_by_user 等数据库表。 在布署时同步构建。
分布数据到切片服务器设计方案
我们组合 切片 ID(shard ID) 、数据类型标识和 局部 ID(local ID) 形成64位的 全局唯一标识(ID) 。切片 ID(shard ID) 占16个位(bit), 数据类型标识占10个位(bit), 局部 ID(local ID) 占36个位(bit)。 明眼人马上会发现,这才62位。我过去的分布及整合数据经验告诉我,保留几位留做扩展是无价宝。因此,我保留了2位(设为0)。(译注:这里解释一下,根据后面的运算和说明,任何对象的唯一标识 ID 是64位,最高2位始终为0,之后是36位的局部标识,之后是10位类型标识,最后是16位的切片标识。局部标识可表示 2^36达600多亿个 ID 。数据类型可表示2^10达1024个对象类型,切片标识可细分成2^16达65536个切片数据库。前面说的方案切了4096个切片数据库)
1
2
3
ID = (shard ID <p>以 Pin: https://www.pinterest.com/pin/241294492511... 为例,让我们解构这个 Pin 对象的 全局 ID 标识 241294492511762325 :</p><pre class="brush:php;toolbar:false">Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429
Type ID = (241294492511762325 >> 36) & 0x3FF = 1
Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
可知这个 Pin 对象在3429切片数据库里。 假设 Pin 对象 数据类型标识为 1,它的记录在3429切片数据库里的 pin 数据表中的 7075733 记录行中。举例,假设切片3429数据库在 MySQL012A中,我们可利用下面语句得到其数据记录:(译注:这里原作者泛泛举例,若按其前面方案例 子来说,3429应在MySQL007A 上)
1
2
conn = MySQLdb.connect(host=”MySQL012A”)
conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
有两种类型的数据:对象或关系。对象包含对象本身细节。 如 Pin 。
存储对象的数据库表
对象库表中的每个记录,表示我们前端业务中的一个对象,诸如:Pins(钉便签), users(用户),boards(白板)和 comments(注释),每个这样的记录在数据库表中设计一个标识 ID 字段(这个字段在表中作为记录的 自增主键「auto-incrementing primary key」 ,也就是我们前面提到的 局部 ID「 local ID」 ),和一个 blob 数据字段 -- 使用 JSON 保存对象的具体数据 --。
1
2
3
4
5
CREATE TABLE pins (
local_id INT PRIMARY KEY AUTO_INCREMENT,
data TEXT,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB;
举例,一个 Pin 对象形状如下:
1
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
创建一个 Pin 对象,收集所有的数据构成 JSON blob 数据。然后,确定它的 切片 ID「 shard ID」 (我们更乐意把 Pin 对象的切片数据放到跟其所在 白板「 board」 对象相同的切片数据库里,这不是强制设计规则)。Pin 对象的数据类型标识为 1。连接到 切片 ID 指示的切片数据库,插入(insert)Pin 对象的 JOSON 数据到 Pin 对象数据库表中,MySQL 操作成功后将会返回 自增主键「auto-incrementing primary key」 给你,这个作为此 Pin 对象的 局部 ID「 local ID」。现在,我们有了 shard 、类型值、local ID 这些必要信息,就可以构建出此 Pin 对象的64位 ID 。(译注:原作者提到的,他们的前端业务所用到的每种对象都保存在一个对象数据库表里,每个对象记录都通过一个全局唯一 ID去找到它,但这个全局唯一 ID并不是数据库表中的 局部ID,由于切片的缘故。原作者一直在讲这个设计及其原理。这样设计的目的为了海量数据切片提高性能,还要易用,可维护,可扩展。后面,作者会依次讲解到)
编辑一个 Pin 对象,使用 MySQL 事务「transaction」 在 Pin 对象的数据记录上 读出--修改--写回「read-modify-write」 Pin 对象的 JOSON 数据字段:
1
2
3
4
5
> BEGIN
> SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE
[修改 json blob]
> UPDATE db03429.pins SET blob=’’ WHERE local_id=7075733
> COMMIT
编辑一个 Pin 对象,您当然可以直接删除这个对象在 MySQL 数据库表中的数据记录。但是,请仔细想一下,是否在对象的 JSON 数据上加个叫做「 active」的域,把剔除工作交由前端中间业务逻辑去处理或许会更好呢。
(译注:学过关系数据库的应知道,自增主键在记录表中是固实,在里面删除记录,会造成孔洞。当多了,势必造成数据库性能下降。数据库只负责保存数据和高性能地查询、读写数据,其数据间的关系完全靠设计精良的对象全局ID通过中间件逻辑去维护 这样的设计理念一直贯穿在作者的行文中。只有理解了这点您才能抓住这篇文章的核心)
关系映射数据库表
关系映射表表示的是前端业务对象间的关系。诸如:一个白板(board)上有哪些钉便签(Pin), 一个钉便签(Pin)在哪些白板(board)上等等。表示这种关系的 MySQL 数据库表包括3个字段:一个64位的「from」ID, 一个64位的「to」ID和一个顺序号。每个字段上都做索引方便快速查询。其记录保存在根据「from」字段 ID 解构出来的切片 ID 指示出的切片数据库上。
1
2
3
4
5
6
CREATE TABLE board_has_pins (
board_id INT,
pin_id INT,
sequence INT,
INDEX(board_id, pin_id, sequence)
) ENGINE=InnoDB;
(译注:这里的关系映射指前端业务对象间的关系用数据库表来运维,并不指我上节注释中说到的关系数据库的关系映射。作者开篇就讲到,由于切片,不能做关系数据库表间的关系映射的,如一对一,一对多,多对多等关系关联)
关系映射表是单向的,如 board_has_pins(板含便签)表方便根据 board (白板)ID查询其上有多少 Pin(钉便签)。若您需要根据 Pin(钉便签)ID查询其都在哪些 board(白板)上,您可另建个表 pin_owned_by_board(便签属于哪些白板)表,其中 sequence 字段表示 Pin 在 board 上的顺序号。(由于数据分布在切片数据库上,我们的 ID 本身无法表示其顺序)我们通常将一个新的 Pin 对象加到 board 上时,将其 sequence 设为当时的系统时间。sequence 可被设为任意整数,设为当时的系统时间,保证新建的对象的 sequence 总是大于旧对象的。这是个方便易行的方法。您可通过下面的语句从关系映射表中查询对象数据集:
1
2
3
SELECT pin_id FROM board_has_pins
WHERE board_id=241294561224164665 ORDER BY sequence
LIMIT 50 OFFSET 150
语句会查出50个 pin_ids(便签 ID ),随后可用这些对象 ID 查询其具体信息。
我们只在业务应用层进行这些关系的映射,如 board_id -> pin_ids -> pin objects (从 白板 ID -> 便签 IDs -> 便签对象)。 这种设计一个非常棒的特性是,您可以分开缓存这些关系映射对。例如,我们缓存 pin_id -> pin object (便签 ID -> 便签对象)关系映射在 memcache(内存缓存)集群服务器上,board_id -> pin_ids (白板 ID -> 便签 IDs)关系映射缓存在 redis 集群服务器上。这样,可以非常适合我们优化缓存技术策略。
增大服务能力
在我们的系统中,提升服务处理能力主要三个途径。最容易的是升级机器(更大的空间,更快的硬盘速度,更多的内存,无论什么解决系统瓶颈的升级都算)
另一个途径,扩大切片范围。最初,我们设计只切片了4096个数据库,相比我们设计的16位的切片 ID,还有许多空间,因为16位可表示65536个数。某些时间节点,若我们再提供8台机器运行8个 MySQL 数据库实例,提供从 4096 到 8192 的切片数据库,之后,新的数据将只往这个区间的切片数据库上存放。并行计算的数据库有16台,服务能力必然提升。
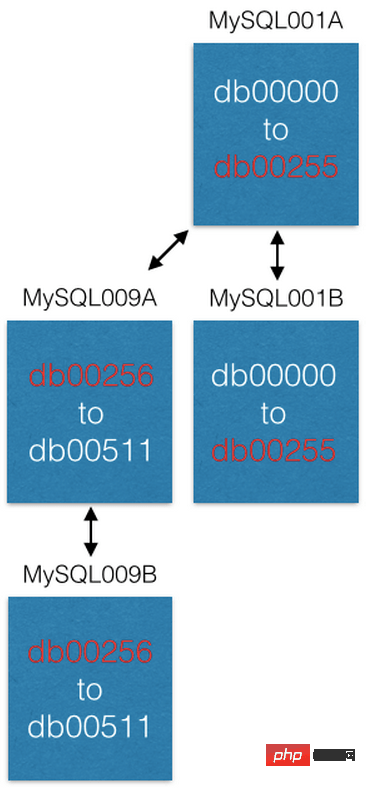
最后的途径,迁移切片数据库主机到新切片主机(局部切片扩容)以提升能力。例如,我们想将前例中的 MySQL001A 切片主机(其上是 0 到 511 编号的切片数据库)扩展分布到2台切片主机上。同我们设计地,我们创建一个新的 master-master 互备份主机对作为新切片主机(命名为 MySQL009A 和 B)并从 MySQL001A 上整体复制数据。

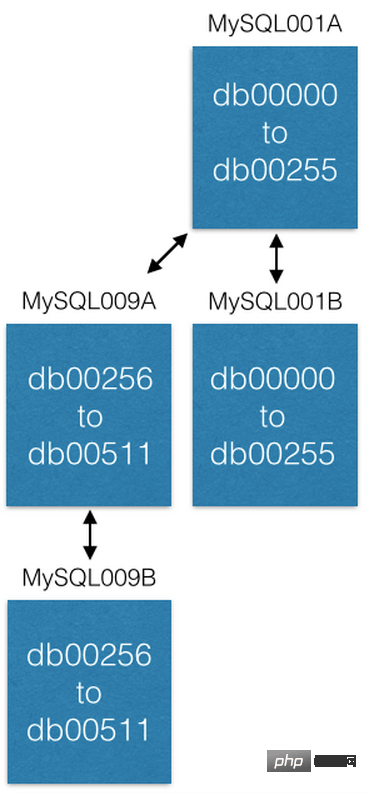
当数据复制完成后,我们修改切片配置,MySQL001A 只负责 0 到 255 的切片数据库,MySQL009A 只负责 256 到 511 的切片数据库。现在2台中每台主机只负责过去主机负责的一半的任务,服务能力提升。
一些特性说明
对于旧系统已产生的业务对象数据,要根据设计,对业务对象要生成它们在新系统中的 UUIDs,你应意识到它们放到哪儿(哪个切片数据库)由你决定。(译注:你可以规划旧数据在切片数据库上的分布)但是,在放入到切片数据库时,只有在插入记录时,数据库才会返回插入对象的 local ID,有了这个,才能构建对象的 UUID。
(译注:在迁移时要考虑好业务对象间关系的建立,通过UUID)对于那些在已有大量数据的数据库表,曾使用过修改表结构类命令 (ALTERs)--诸如添加个字段之类的 -- 的人来说,您知道那是一个 非常 漫长和痛苦的过程。我们的设计是绝不使用 MySQL 上 ALTERs 级别的命令(当已有数据时)。在我们的业务系统 Pinterest 上,我们使用最后一个 ALTER 语句大概是在3年前了。 对于对象表中对象,如果您需要添加个对象属性字段,您添加到对象数据的 JOSON blob 字段里。您可以给新对象属性设定个默认值,当访问到旧对象的数据时,若旧对象没有新属性,您可以给其添加上新属性默认值。对于关系映射表来说,干脆,直接建立新的关系映射表以符合您的需要。这些您都清楚了!让您的系统扬帆起行吧!
模转(mod)数据库的切片
模转数据切片(mod shard)名称仅仅是像 Mod Squad,实则完全不同。
一些业务对象需要通过非 ID (non-ID)的方式查询访问。(译注: 此 ID 指之前设计说明中的64位 UUID)举例来说,如果一名 Pin友(Pinner)是以他(她)的 facebook 注册帐号注册登录我们的业务平台上的。我们需将其 facebook ID 与我们的 Pin友(Pinner)的 ID 映射。 facebook ID 对于我们系统只是一串二进制位的数。(译注:暗示我们不能像我们系统平台的设计那样解构别的平台的 ID,也谈不上如何设计切片,只是把它们保存起来,并设计使之与我们的 ID 映射)因此,我们需要保存它们,也需要把它们分别保存在切片数据库上。我们称之为模转数据切片(mod shard)其它的例子还包括 IP 地址、用户名和用户电子邮件等。
模转数据切片(mod shard)类似前述我们业务系统的数据切片设计。但是,你需要按照其输入的原样进行查询。如何确定其切片位置,需要用到哈希和模数运算。哈希函数将任意字串转换成定长数值,而模数设为系统已有切片数据库的切片数量,取模后,其必然落在某个切片数据库上。结果是其数据将保存在已有切片数据库上。举例:
1
shard = md5(“1.2.3.4") % 4096
(译注:mod shard 这个词,我网上找遍了,试图找到一个较准确权威的中文翻译!无果,因为 mod 这个词有几种意思,最近的是module 模块、模组,同时它也是模运算符(%)。我根据原文意思,翻译为 模转 。或可翻译为 模式,但个人感觉意思模糊。不当之处,请指正。另,原作者举的例子是以 IP 地址举例的,哈希使用的是 md5,相比其它,虽老但性能最好)
在这个例子中分片是1524。 我们维护一个类似于ID分片的配置文件:
1
2
3
4
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”},
{“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”},
{“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”},
…]
因此,为了找到 IP 为1.2.3.4的数据,我们将这样做:
1
2
conn = MySQLdb.connect(host=”msdb003a”)
conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip=1.2.3.4”)
你失去了一些分片好的属性,例如空间位置。你必须从一开始就设置分片的密钥(它不会为你制作密钥)。最好使用不变的id来表示系统中的对象。这样,当用户更改其用户名时,您就不必更新许多引用。
最后的提醒
这个系统作为 Pinterest 的数据支撑已良好运行了3.5年,现在看来还会继续运行下去。设计实现这样的系统是直观、容易的。但是让它运行起来,尤其迁移旧数据却太不易了。若您的业务平台面临着急速增长的痛苦且您想切片自己的数据库。建议您考虑建立一个后端集群服务器(优先建议 pyres)脚本化您迁移旧数据到切片数据库的逻辑,自动化处理。我保证无论您想得多周到,多努力,您一定会丢数据或丢失数据之间的关联。我真的恨死隐藏在复杂数据关系中的那些捣蛋鬼。因此,您需要不断地迁移,修正,再迁移... 你需要极大的耐心和努力。直到您确定您不再需要为了旧数据迁移而往您的切片数据库中再操作数据为止。
这个系统的设计为了数据的分布切片,已尽最大的努力做到最好。它本身不能提供给你数据库事务 ACID 四要素中的 Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)哇呕!听起来很坏呀,不用担心。您可能不能利用数据库本身提供的功能很好地保证这些。但是,我提醒您,一切尽在您的掌握中,您只是让它运行起来,满足您的需要就好。设计简单直接就是王道,(译注:也许需要您做许多底层工作,但一切都在您的控制之中)主要是它运行起来超快! 如果您担心 A(原子性)、I(隔离性)和 C(一致性),写信给我,我有成堆的经验让您克服这些问题。
还有最后的问题,如何灾难恢复,啊哈? 我们创建另外的服务去维护着切片数据库,我们保存切片配置在 ZooKeeper 上。当单点主服务器宕掉时,我们有脚本自动地提升主服务器对应的从服务器立即顶上。之后,以最快的速度运行新机器顶上从服务器的缺。直至今日,我们从未使用过类似自动灾难恢复的服务。
以上就是Pinterest MySQL实践利用分片来解决百亿数据的存储问题的详细内容,更多请关注其它相关文章!