在 2026 年,大规模数据采集(Web Scraping)已经演变成一场高强度的“攻防战”。传统的机房 IP 代理在面对大厂(如 Amazon, Google, Shopee)自研的 AI 风险引擎时,几乎一触即溃。
住宅代理(Residential Proxy) 已成为千万级采集任务的唯一生命线。但如何高效、稳定地在 Python 代码中调度这些数以百万计的 IP?本文将从零开始,手把手教你构建一套工业级的分布式采集系统。
一、 核心痛点:为什么传统的采集方案会失效?
在编写代码前,我们必须理解 2026 年反爬虫系统的三个核心监控维度:
- IP 信誉度(IP Reputation): 大数据会分析每一个 IP 的历史行为。如果一个 IP 地址的 ASN 显示为机房(Datacenter),且在短时间内发出了数千次请求,会被立即判定为机器人。
-
TLS 指纹(JA3/JA4): 这是很多初级开发者忽略的。即使你换了 IP,如果你使用的是 Python 的
requests库,其底层的 SSL 握手特征是完全一致的。高级防火墙可以通过 JA3 指纹直接定位到你正在使用自动化脚本。 - 行为生物识别(Behavioral Analysis): 请求频率过于规律(如每隔 1 秒请求一次)、没有加载静态资源(JS/CSS)、或者是缺失复杂的 HTTP 报头信息。
二、 住宅代理 API 的两种调度策略深度对比
1. 自动轮换隧道模式 (Rotating Proxy Tunnel)
你只需要在代码中配置一个固定入口(Host:Port),每发起一次请求,代理服务商的网关会自动为你分配一个新的住宅 IP。
- 适用场景: 小型采集任务、对 IP 存活时间无要求的任务。
- 接入成本: 极低,几乎不改动原有代码逻辑。
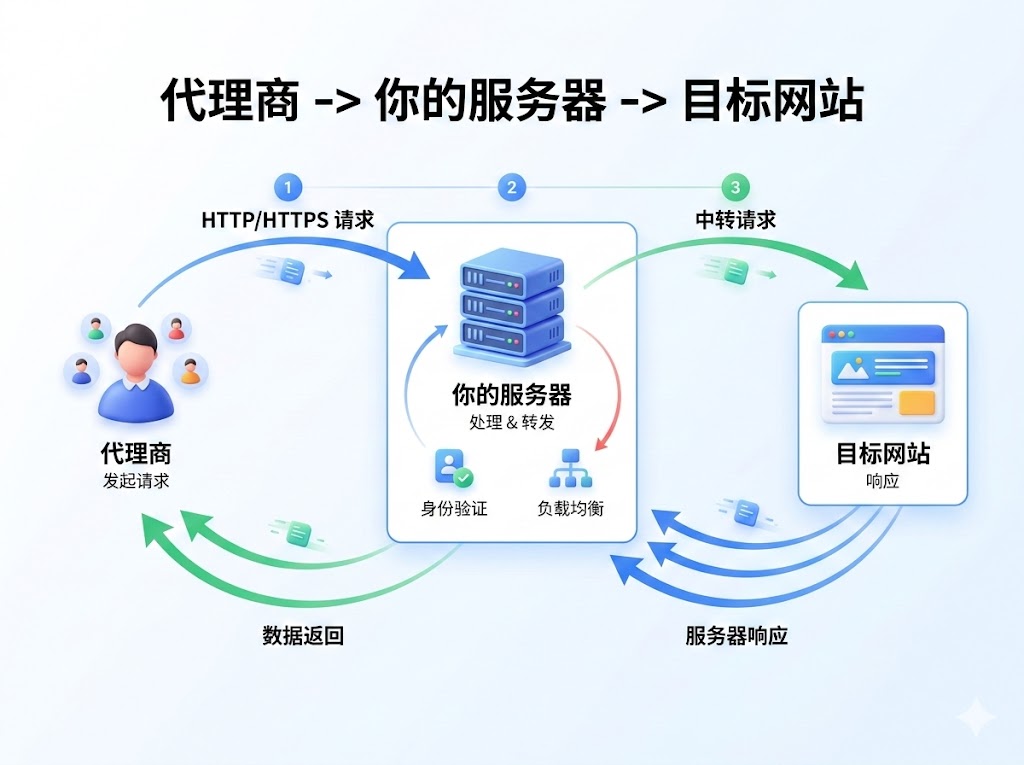
2. API 批量提取模式 (IP Whitelist / API Pulling)
通过调用 API 接口(如:http://api.zvvq.cn/get_ip?num=100)一次性获取几百个 IP 地址,由你的本地程序决定何时切换。
- 适用场景: 千万级分布式任务、需要保持 Session 登录状态的场景。
- 控制力: 极强。你可以手动剔除响应慢的 IP。
三、 工业级 Python 采集框架实现(含高级逻辑)
为了让代码更具实战价值,我们引入 httpx(支持 HTTP/2)和 retrying 库,并加入动态 User-Agent 伪装。
1. 环境依赖安装
pip install httpx[http2] retrying fake-useragent
2. 核心代码架构实现
import httpx
from retrying import retry
from fake_useragent import UserAgent
import random
import logging
# 配置日志,方便千万级任务监控
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
ua = UserAgent()
# 模拟 ZVVQ 合作代理商 API 接口
PROXY_POOL_URL = "http://api.your_proxy_provider.com/get_ip?auth=SECRET&num=5"
class ScraperSystem:
def __init__(self):
self.proxy_pool = []
self.current_proxy = None
def refresh_proxy_pool(self):
"""批量获取 IP,降低 API 调用频率"""
try:
logging.info("正在更新代理池...")
resp = httpx.get(PROXY_POOL_URL, timeout=5)
if resp.status_code == 200:
# 假设返回的是换行符分割的 IP:Port
self.proxy_pool = resp.text.strip().split('
')
logging.info(f"成功获取 {len(self.proxy_pool)} 个新住宅 IP")
except Exception as e:
logging.error(f"代理池更新失败: {e}")
def get_proxy(self):
"""从本地池中弹出一个 IP"""
if not self.proxy_pool:
self.refresh_proxy_pool()
if self.proxy_pool:
p = self.proxy_pool.pop(0)
return {"http://": f"http://{p}", "https://": f"http://{p}"}
return None
@retry(stop_max_attempt_number=5, wait_fixed=2000)
def fetch_page(self, url):
"""核心采集逻辑,含自动重试"""
proxy = self.get_proxy()
if not proxy:
raise Exception("暂无可用代理")
# 构造高仿真 Header
headers = {
"User-Agent": ua.random,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
}
# 使用 httpx 开启 HTTP/2 支持,绕过部分针对 HTTP/1.1 的封锁
with httpx.Client(proxies=proxy, headers=headers, http2=True, timeout=12) as client:
logging.info(f"正在使用代理 {proxy['http://']} 请求: {url}")
response = client.get(url)
if response.status_code == 200:
return response.text
elif response.status_code in [403, 429]:
logging.warning(f"触发风控 ({response.status_code}),准备重试并换 IP...")
raise Exception("Triggered anti-spider")
else:
raise Exception(f"HTTP 错误: {response.status_code}")
if __name__ == "__main__":
scraper = ScraperSystem()
target_tasks = ["https://example.com/item/1", "https://example.com/item/2"] # 模拟千万级列表
for task in target_tasks:
try:
html = scraper.fetch_page(task)
logging.info(f"成功抓取长度: {len(html)}")
except Exception as e:
logging.error(f"任务失败: {task}, 原因: {e}")
四、 进阶:如何攻克 2026 年的高级反爬关卡?
1. 解决 TLS 指纹识别 (JA3)
很多大厂防火墙会检查你的 SSL 握手特征。如果你的 Python requests 被识破,可以尝试使用 curl_cffi 库,它可以完美模拟真实 Chrome 浏览器的 TLS 指纹。
2. 分布式架构 (Scrapy + Redis)
单机采集千万级数据是不现实的。建议将任务存入 Redis 队列,利用多台服务器(每台配置不同的住宅代理账号)并行消费。
3. IP 预热与冷却逻辑
对于住宅代理,建议建立一个“黑名单缓存”。一旦某个 IP 连续 3 次请求失败,将其存入 Redis 并设置 1 小时过期待审,避免无效请求浪费代理点数。
五、 2026 年住宅代理 API 服务商推荐
通过 ZVVQ 代理分享网的长期压力测试,以下三家在 Python 集成方面表现最稳:
- 9Proxy (高爆发首选): API 响应极快,非常适合对实时性要求高的数据采集。
- LumiProxy (长效养号/精准采集): 提供极佳的城市级定位 API,如果你需要采集特定的地区价格信息,它是首选。
- Bright Data (企业级): 拥有最复杂的 API 控制参数,支持直接在云端运行爬虫。
结语
千万级数据采集不是简单的“暴力请求”,而是代理资源、伪装技术、以及代码鲁棒性的综合体现。通过合理调用住宅代理 API,并配合 HTTP/2、TLS 指纹模拟等前沿技术,你才能在数据竞争中立于不败之地。
想要获取上述代码的完整分布式版本,或者针对特定网站的爬虫方案?请在评论区留言,并注明你的报错码!