综合多篇权威资料整理而成,帮助您长期稳定地获取数据
频繁出现验证码、HTTP 403/429状态码或延迟激增时需调整策略
约14%顶级网站采用主动屏蔽(如AI指纹检测),需持续更新对抗手段
违反robots.txt或数据法规可能导致诉讼,商业爬取前务必咨询法律意见
本指南综合了以下专业爬虫服务商的研究成果:
实践时建议结合
避免网站爬取时被封禁的15个核心技巧
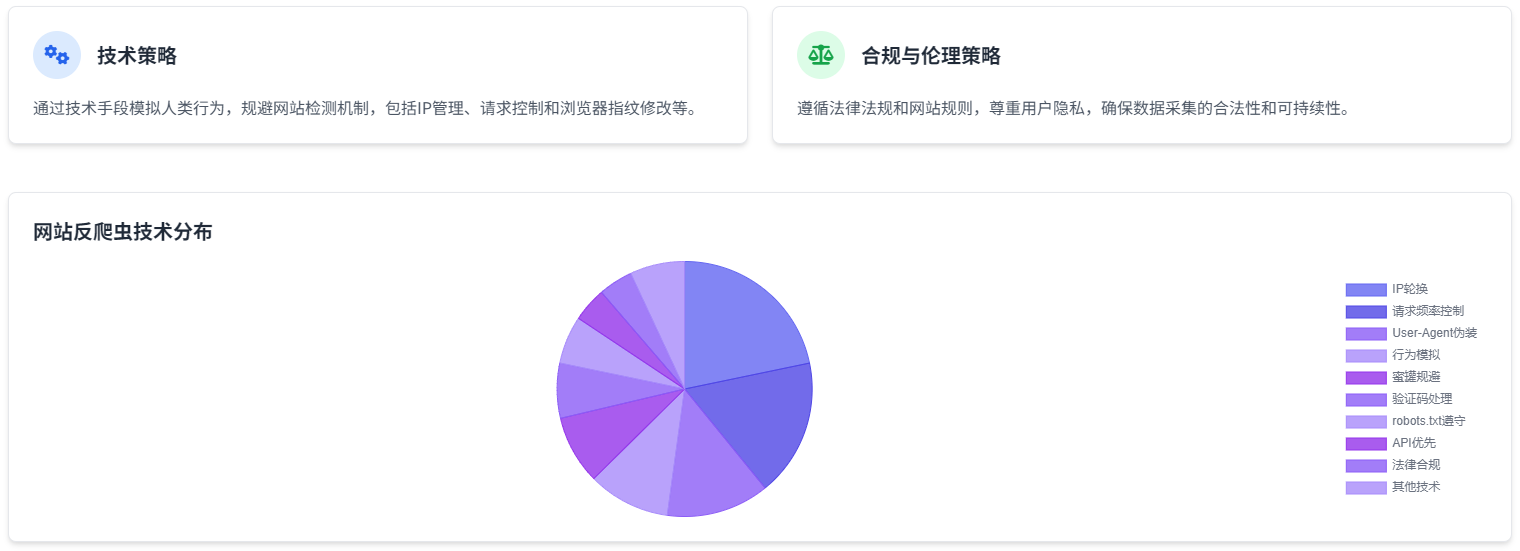
技术策略
轮换IP地址
设置合法用户代理
控制请求频率
模拟人类行为
使用无头浏览器
规避蜜罐陷阱
利用Google缓存
处理验证码
设置合法来源
复用Cookies
合规与伦理策略
遵守robots.txt协议
避免敏感数据
合规数据使用
优先使用官方API
主动沟通授权
关键注意事项
检测封禁信号
技术对抗局限
法律风险
参考来源
requests/Scrapy等库的延迟设置和代理中间件实现。
避免网站爬取时被封禁的15个核心技巧
作者:zvvq博客网
免责声明:本文来源于网络,如有侵权请联系我们!