要使用Python抓取Google搜索结果,可以参考以下几种方法和工具。需要注意的是,直接抓取Google搜索结果可能会遇到反爬虫机制,如CAPTCHA,因此建议使用官方API或第三方服务来简化过程。
提供多种实现方式的完整代码示例
了解如何应对Google的反爬虫机制
获取稳定可靠搜索结果的最佳方法
首先,安装所需的库:
以下是一个简单的示例代码,用于抓取Google搜索结果:
首先,安装ScrapingBee库:
以下是一个使用ScrapingBee API抓取Google搜索结果的示例代码:
首先,安装Selenium库和浏览器驱动(如ChromeDriver):
以下是一个使用Selenium抓取Google搜索结果的示例代码:
Google有很强的反爬虫机制,频繁请求可能会导致IP被封禁。建议使用代理或API来避免这个问题。
确保你的抓取行为符合Google的服务条款和相关法律法规。
Google搜索结果页面可能包含动态加载的内容,使用Selenium等工具可以更好地处理这种情况。
通过以上方法,你可以使用Python有效地抓取Google搜索结果。选择合适的方法取决于你的具体需求和技术背景。
ScrapingBee > Requests > Selenium
ScrapingBee > Requests > Selenium
Requests < ScrapingBee < Selenium
Python抓取Google搜索结果指南
代码示例
反爬虫应对
最佳实践
方法一:使用第三方库(BeautifulSoup和requests)
安装依赖
pip install beautifulsoup4 requests
示例代码
import requests
from bs4 import BeautifulSoup
# 替换为你想要搜索的关键词
keyword = 'Python'
# 构造请求URL
url = f'https://www.google.com/search?q={keyword}'
# 发送请求并获取响应
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取搜索结果
results = soup.find_all('h3', class_='LC20lb MBeuO DKV0Md')
# 打印搜索结果
for result in results:
print(result.text.strip())
else:
print('请求失败,状态码:', response.status_code)
方法二:使用ScrapingBee API
安装依赖
pip install scrapingbee
示例代码
from scrapingbee import ScrapingBeeClient
# 替换为你的ScrapingBee API密钥
api_key = 'YOUR_API_KEY'
# 创建ScrapingBee客户端
client = ScrapingBeeClient(api_key=api_key)
# 替换为你想要搜索的关键词
keyword = 'Python'
# 构造请求URL
url = f'https://www.google.com/search?q={keyword}'
# 发送请求并获取响应
response = client.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 提取搜索结果
results = soup.find_all('h3', class_='LC20lb MBeuO DKV0Md')
# 打印搜索结果
for result in results:
print(result.text.strip())
else:
print('请求失败,状态码:', response.status_code)
方法三:使用Selenium
安装依赖
pip install selenium
示例代码
from selenium import webdriver
from selenium.webdriver.common.by import By
# 创建WebDriver实例
driver = webdriver.Chrome()
# 替换为你想要搜索的关键词
keyword = 'Python'
# 构造请求URL
url = f'https://www.google.com/search?q={keyword}'
# 打开URL
driver.get(url)
# 等待页面加载完成
driver.implicitly_wait(10)
# 提取搜索结果
results = driver.find_elements(By.CSS_SELECTOR, 'h3.LC20lb.MBeuO.DKV0Md')
# 打印搜索结果
for result in results:
print(result.text)
# 关闭浏览器
driver.quit()
注意事项
反爬虫机制
合法性
动态内容
方法对比
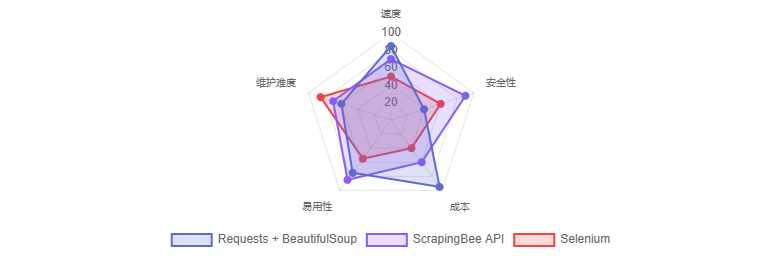
总结
速度
安全性
成本
Python抓取Google搜索结果指南
作者:zvvq博客网
1
2
3
1
2
3
免责声明:本文来源于网络,如有侵权请联系我们!