探索Python在Web数据抓取中的应用、工具和最佳实践
使用Python进行Web Scraping(网络爬虫)与现代Web的数据提取
Python优势
Python是一种简单而强大的编程语言,非常适合用于Web Scraping。它提供了多种库和工具,使得从网页中提取数据变得相对简单和灵活。
应用场景
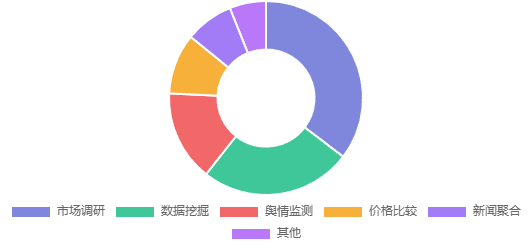
Web Scraping的应用场景非常广泛,包括市场调研、数据挖掘、舆情监测、价格比较、新闻聚合等,帮助从各种网站获取有价值的数据。
安全挑战
为了确保Web Scraping的顺利进行,需要避免触发网站的抓取陷阱和机器人阻止器,通过设置合理的请求间隔、使用代理IP等方式来避免被网站封禁。
Web Scraping的基本步骤
发送HTTP请求
使用库如urllib、urllib2、PycURL等来发送HTTP请求,获取网页内容。
解析HTML页面
使用库如BeautifulSoup、lxml等来解析HTML页面,提取所需的数据。
提取所需数据
通过编写脚本,从解析后的HTML中提取特定的数据元素。
存储数据
将提取的数据存储到数据库、CSV文件或JSON文件中,以便进一步分析和处理。
常用的Python库
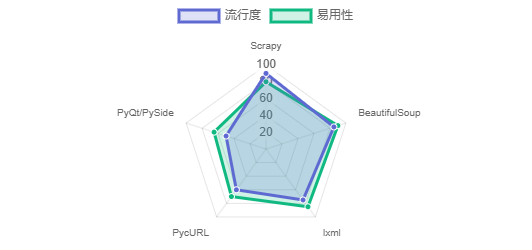
Scrapy
一个快速、高级的Web爬虫框架,用于抓取网站、解析和提取结构化数据。
BeautifulSoup
一个Python HTML/XML解析器,适用于快速的屏幕抓取项目。
lxml
一个Pythonic绑定库,基于C语言的libxml2和libxslt,可以解析HTML页面并使用XPath选择DOM元素。
PycURL
一个Python接口,基于libcurl,用于从URL获取对象。
PyQt 和 PySide
提供WebKit包,可以浏览网页并进行网页提取。
处理现代Web的挑战
现代Web页面通常包含大量的JavaScript动态内容,这给Web Scraping带来了挑战。
解决方案
- 使用像PyQt或PySide这样的库,它们包含WebKit包,能够处理JavaScript代码
- 使用Scrapy框架来开发更复杂的爬虫,以应对各种网络抓取场景
示例代码
from PyQt5.QtWebEngineWidgets import QWebEngineView
from PyQt5.QtCore import QTimer
class WebScraper(QWebEngineView):
def __init__(self, url):
super().__init__()
self.load(url)
# 等待页面加载完成
QTimer.singleShot(5000, self.process_page)
def process_page(self):
# 在这里处理页面内容
pass
# 使用示例
scraper = WebScraper("https://example.com")
数据清洗与规范化
在Web Scraping过程中,经常会遇到格式不一致、拼写错误等问题。因此,数据清洗和规范化是非常重要的步骤。
常用方法
- 使用正则表达式清理数据
- 使用字符串操作标准化文本
- 去除HTML标签和特殊字符
- 统一日期和数字格式
示例代码
import re
def clean_text(text):
# 移除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 移除特殊字符
text = re.sub(r'[^\w\s]', '', text)
# 统一空格
text = re.sub(r'\s+', ' ', text).strip()
return text
# 使用示例
raw_data = "<p>商品价格: ¥9,999.00 </p>"
cleaned_data = clean_text(raw_data)
print(cleaned_data) # 输出: 商品价格 999900
Python库使用情况
Web Scraping应用场景
最佳实践
- 设置合理的请求间隔,避免触发网站的反爬虫机制
- 使用User-Agent轮换,模拟不同浏览器访问
- 尊重robots.txt文件,避免抓取禁止访问的内容
- 使用代理IP池,分散请求来源
- 定期更新爬虫代码,适应网站结构变化
总结
使用Python进行Web Scraping是一种高效的数据提取方法,可以帮助我们快速获取互联网上的大量数据,并进行进一步的分析和处理。通过掌握Python的各种库和工具,可以应对现代Web的各种挑战,实现复杂的数据抓取任务。
下一步学习建议
- 深入研究Scrapy框架的高级功能
- 学习如何处理JavaScript渲染的网页
- 了解分布式爬虫的实现方式
- 研究API接口的数据抓取技术
- 掌握数据存储的最佳实践