mysql里面的分布式方案其实挺丰富的,今天来简单说下对分布式方案的理解。 zvvq
推荐课程:MySQL教程 zvvq.cn
 zvvq.cn
zvvq.cn
首先数据库是一个软件,最基础的功能就是数据存储和数据查询。对于数据的处理方式如果通泛来说是分为读和写,所以分布式方案的很多场景其实也是围绕着这两个维度来做的。 内容来自samhan
在开始分布式方案前,要说下为什么要有分布式方案。如果单机可以解决的事情,其实完全没有必要去再考虑分布式了。如果要分,其实就不能再很自然的合起来,这也是分布式方案里需要掌握的一个平衡。 现在行业里说的HTAP方案,其实就是融合了OLTP+OLAP的场景,如果从单机的角度来说,Oracle肯定是最好的HTAP解决方案了。 但是oracle里面除了价格的问题之外,还有一个问题,那就是扩展性,暂不说sharding的细节,Oracle里面的设计思想就是share everything,所以分区表的方案还是比较合适的。
但是MySQL显然不行,因为你几乎听不到互联网行业里在用分区表的方案,因为再怎么分,怎么扩展,数据都是在单机上,况且单机性能还差强人意。 所以单机容量,单机性能都是一个瓶颈,那么就可以有两个或者多个实例来分担压力。
我来简单举个例子。从数据的处理角度来说,数据有读写需求,那么我们的需求就可以分别对读需求和写需求做扩展。 copyright zvvq
读需求的扩展相对来说简单一些,就是常说的读写分离了。这种一般的中间件都可以支持。
内容来自zvvq
就如同下图的方案里面的左下角所示,对读的需求可以轻松实现读扩展,这里的读扩展是线性的,不是指数级的,对业务来说是透明的。 copyright zvvq
难点就在于写扩展了,写扩展的核心是涉及到分布式事务的部分,能不拆就不拆,如果实在要拆,那么我们可以分不同的维度,比如对于流水型数据,这类数据的前后依赖度很低,所以写需求就是insert,写的需求比较单一。这种方式可以使用中间件的方案来辅助,做到sharding的分片方案。 我们通常理解的分布式方案其实很多也是在说这个。这种方案的扩展是指数级别的,比如2个节点,变为4个,4个变为8个等等,对业务算是透明的。 本文来自zvvq
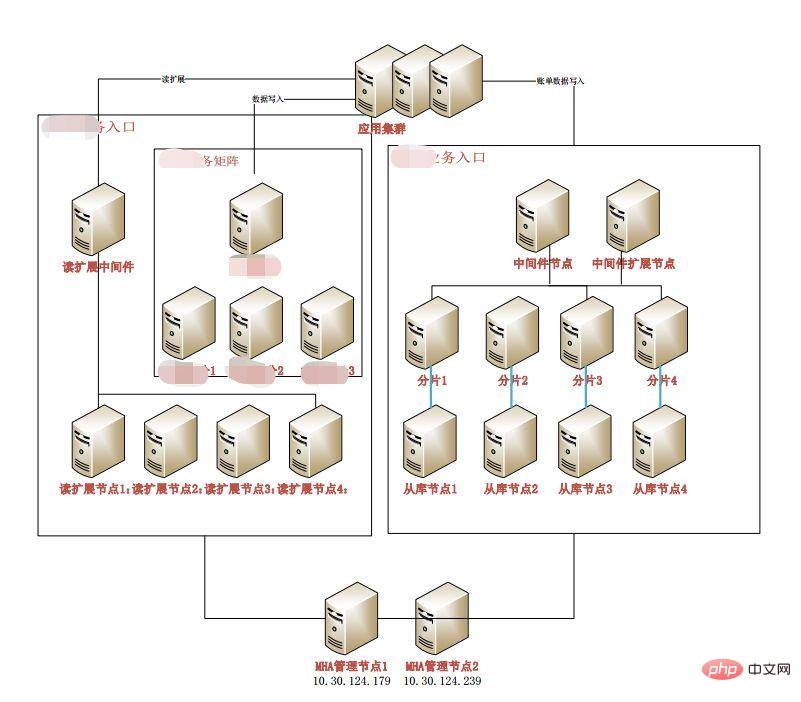 内容来自samhan666
内容来自samhan666
但是还有一类更为复杂的,那就是状态型数据,我们不能直接拆,或者说直接分片,我们可以根据业务的维度来拆分,这种拆分就不建议直接使用中间件了。 比如一个业务如果拆分可以拆分为业务1,业务2,业务3。。。业务8,那么这8个业务的拆分逻辑建议不是做成hash的平滑方式,而是建议根据业务逻辑的优先级和其他维度来组合,比如业务1的优先级高,那么完全可以是一个独立的节点,业务3-业务6的数据量和优先级不同,则完全可以是一个节点。数据的写入路由规则建议还是通过应用层面来进行处理。这是一种更加可控的方案。这种扩展方案对应用不是透明的,需要应用的配合和处理。但是收益也显然是最佳的平衡状态,比如游戏行业里很常见的游戏服概念,就是这种分法,所以扩展起来可以是线性的。 zvvq.cn
如果要说这个基础之上的分布式方案,其实是把一套集群或者业务当做一个透明的节点,使用其他的辅助方案来达到扩展的需求,基于关系型的分布式方案更多是基于静态路由来处理,对于扩容来说还是需要做很多额外的工作,没法做到平滑的弹性。这一点上自然是NoSQL,NewSQL的用武之地了。
本文来自zvvq
所以在方案的选择上,要有大局观和更高的视野,不一定什么都是MySQL,Oracle,深耕下去自然是不错的,还可以考虑其他更好的方案。
本文来自zvvq
以上就是mysql支持分布式吗的详细内容,更多请关注其它相关文章!